Attention 구현하기
개요
- Image captioning과 번역기 등과 같은 자연어 처리 분야는 인공지능이 활발하게 쓰이는 대표적인 분야이다.
- Recurrent Neaural Network(RNN)의 등장으로 큰 도약이 있었지만 여전히 문제가 존재했다.
- 다음에는 Long Short Term Memory(LSTM)이 등장하며 기존 RNN의 문제인 정보의 손실을 최소화할 수 있었다.
- 그 후, Encoder-Decoder를 활용한 Seq2Seq모델이 등장하여 문맥의 파악이 가능해졌다.
- 하지만 여전히 입력문장이 매우 길면 정확도가 확연히 줄어드는 현상이 남아있다.
-
Attention은 위의 문제를 타파하기 위해 고안된 방법이다.
- Seq2Seq 네트워크의 형태
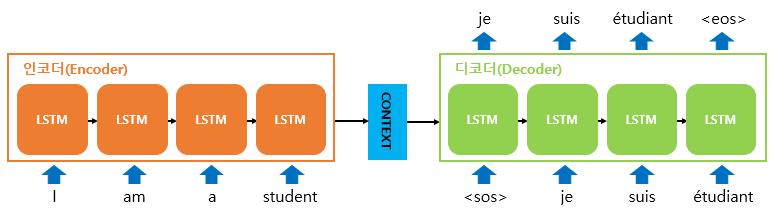
- 인코더를 통해 입력받은 문장을 context vector형태로 만들고, 이를 디코더에 넣어서 output을 도출한다.
- 인코더와 디코더는 모두 LSTM으로 구성되어 있다.
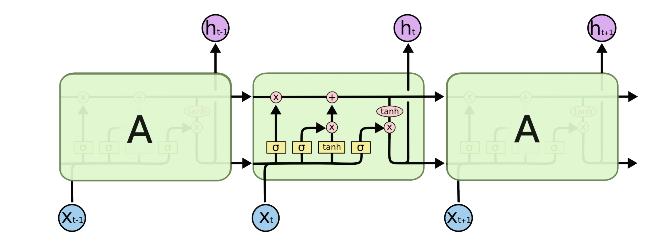
- LSTM은 아래와 같은 형태이다.
- Seq2Seq 모델에는 2가지의 문제가 존재한다.
- 하나의 고정된 크기의 벡터에 모든 정보를 압축하려다보니 정보 손실이 발생한다.
- Vanishing gradient가 심하다.
Attention 원리
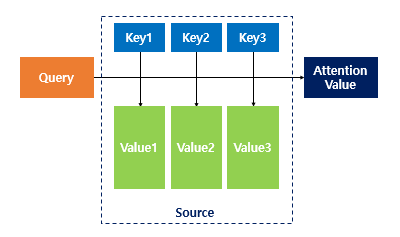
- Attention(Q, K, V)는 다음과 같이 정의된다.
- Q(Query): t시점의 디코더 셀에서의 hidden state
- K(Key): 모든 시점의 인코더 셀의 hidden state
- V(Value): 모든 시점의 인코더 셀의 hidden state
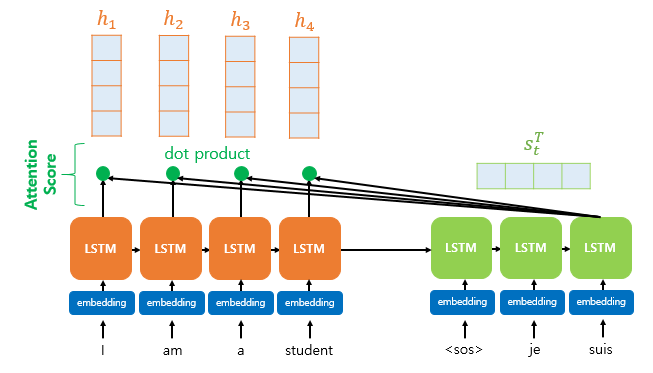
- 그림과 같이 출력 단어를 예측하기 위해 Attention Score가 필요하다. Attention Score는 현재 디코더의 시점 t에서 단어를 예측하기 위해, 인코더의 모든 hidden state 각각이 디코더의 현 시점의 hidden state s_t와 얼마나 유사한지를 판단하는 값이다.
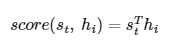
- score는 위와 같이 구해지고, 스칼라 값을 갖는다.
- 각 시점의 Score들을 list에 넣어서 벡터를 만들고, 그 벡터를 softmax를 하여 Attention Distribution을 만든다.
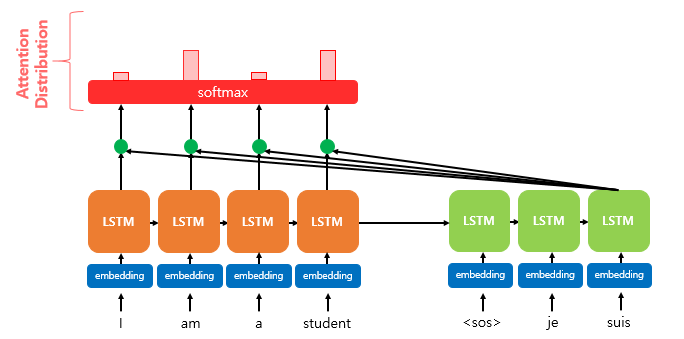
- 이를 통해 각 시점 t에서의 Attention 가중치 모음을 구할 수 있다.
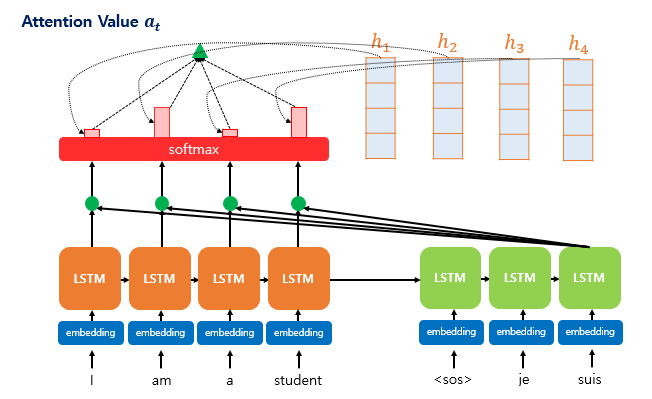
- 그 후, 인코더의 각 hidden state와 softmax로 구한 가중치들을 곱하고 전부 더하여 Attention Value를 구한다. 이 값은 스칼라 형태이다.
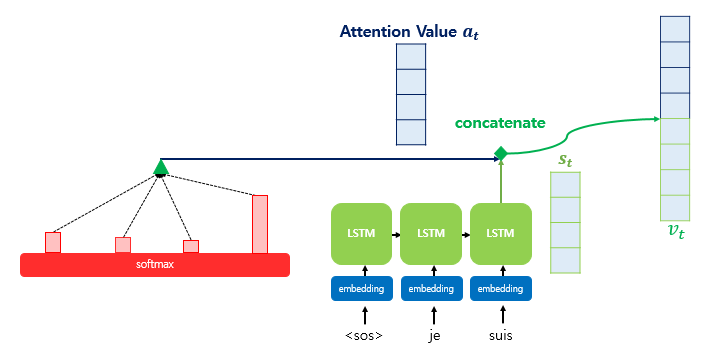
- 위 그림과 같이 Attention Value와 디코더의 현 시점 hidden state인 s_t를 결합(concatenate)하여 context vector를 만든다.
- Seq2Seq의 인코더의 마지막 hidden state가 context vector인 것보다 정보의 손실이 적다.
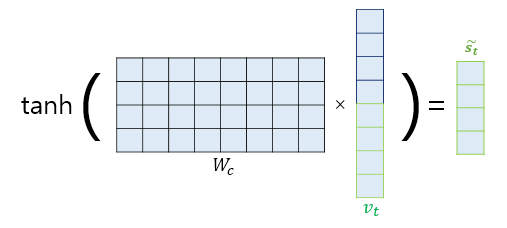
- 출력층으로 들어가기 앞서 결합된 벡터 v_t를 tanh함수를 activation function으로 갖는 FC를 지나게 하여 출력층의 입력값 ~s_t를 구한다.
- 출력층을 통과한 벡터를 softmax를 통해 확률분포로 만들어주면 예측값이 나온다.